浏览器解码看XSS

浏览器解码看XSS
浏览器解码规则
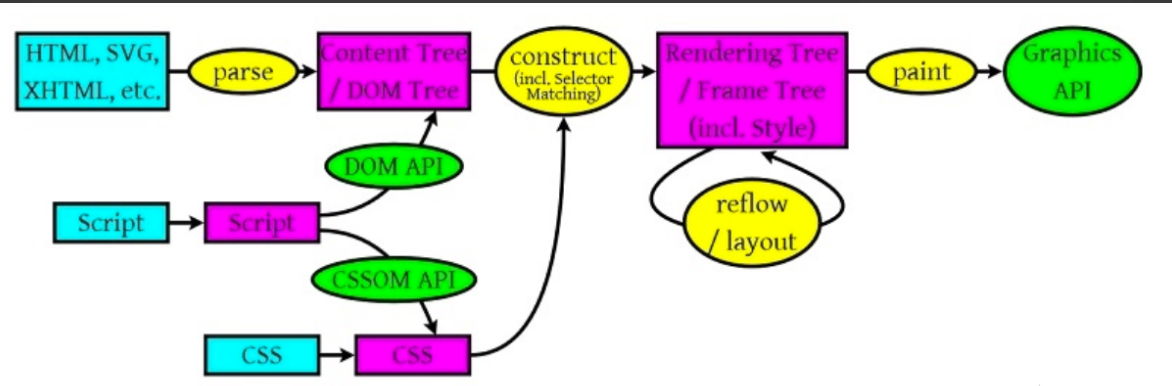
浏览器无论什么情况都会遵守一个这样的解码规则:
HTML编解码
HTML解析器
HTML中有五类元素:
- 空元素(Void elements),如
<area>,<br>,<base>等等 - 原始文本元素(Raw text elements),有
<script>和<style> - RCDATA元素(RCDATA elements),有
<textarea>和<title> - 外部元素(Foreign elements),例如MathML命名空间或者SVG命名空间的元素
- 基本元素(Normal elements),即除了以上4种元素以外的元素
五类元素的区别如下:
- 空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
- 原始文本元素,可以容纳文本。
- RCDATA元素,可以容纳文本和字符引用。
- 外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
- 基本元素,可以容纳文本、字符引用、其他元素和注释
HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个<符号(后面没有跟/符号)就会进入“标签开始状态(Tag
open state)”。然后转变到“标签名状态(Tag name state)”,“前属性名状态(before attribute name
state)”……最后进入“数据状态(Data state)”并释放当前标签的token。当解析器处于“数据状态(Data
state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
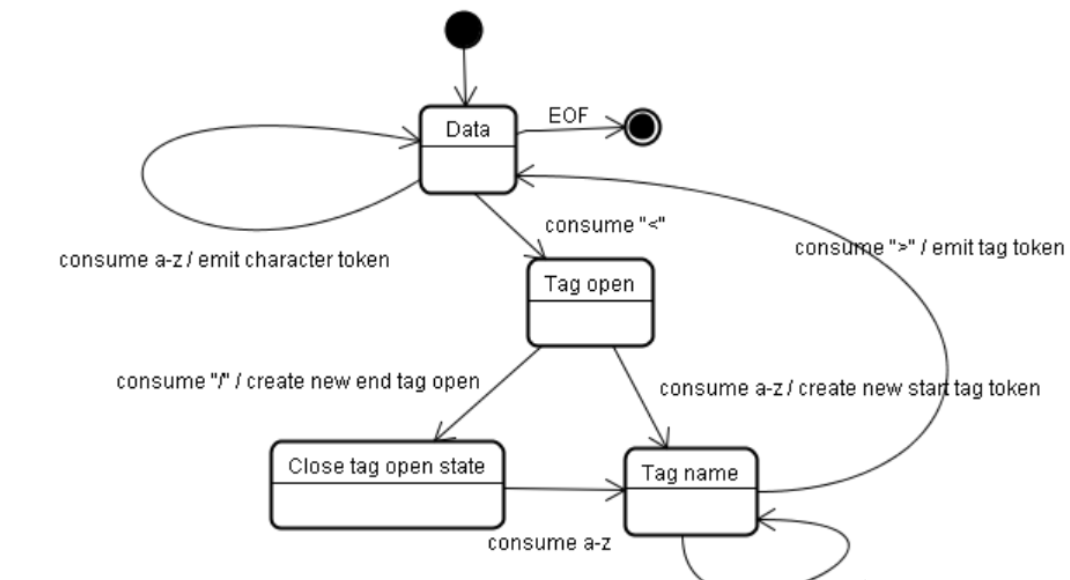
举个栗子:
存在<h1>hhhhhhhh</h1> ,首先状态机吃下< 进入标签开始状态然后转变到标签名状态开始匹配标签
当吃进去/>标签的时候进入标签结束状态然后进入Data state状态
一般来说HTML编码需要在Data State 状态下进行
例如如果存在<h1>hhhhh</h1> 那么就无法解析这个编码
但是如果是<h1>hhhhhhhhh</h1> 却能够正确成功的解析
HTML状态机可容纳RCDATA状态中的字符引用,这意味着在<textarea>和<title>标签中的字符引用会被HTML解析器解码,对RCDATA有个特殊的情况。在浏览器解析RCDATA元素的过程中,解析器会进入“RCDATA状态”。在这个状态中,如果遇到<字符,它会转换到RCDATA小于号状态。如果<字符后没有紧跟着/和对应的标签名,解析器会转换回RCDATA状态。这意味着在RCDATA元素标签的内容中(例如<textarea>或<title>的内容中),唯一能够被解析器认做是标签的就是</textarea>或者</title>。当然,这要看开始标签是哪一个。因此,在<textarea>和<title>的内容中不会创建标签,不会有脚本执行。
在建立好DOM语法树之后浏览器开始进行一个url或者js解码
意味着你如果在JS标签中使用HTML实体编码是没有用的
例如:<script>alert('1')</script>
但是如果存在代码<svg><script>alert(1)</script> 就能够弹窗了
原因是<svg>遵循XML和SVG的定义。
我们知道,在XML中,(会被解析成(
那么对于<svg>而言同样遵守XML的规则进行解析
师傅的总结:https://www.hackersb.cn/hacker/85.html
javascript编解码
说完了解码的第一步,接下来就是JS解码或者URL解码
JS编码的规则相对来说比较严谨,它对除了阿拉伯数字和字母外的东西都进行了一个编码
最常用的如\uXXXX这种写法为Unicode转义序列,表示一个字符,其中xxxx表示一个16进制数字,如< Unicode编码为\u003c。
如果有代码<img src="1" onerror=\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0029>
但是无法执行???
我们以浏览器的视角来看:首先读到<开始读取标签,然后读到onerror调用js解析器。在js中,单引号,双引号和圆括号等属于控制字符,编码后将无法识别。所以对于防御来说,应该编码这些控制字符。下面这种方式可以解析。
<img src="1" onerror=\u0061\u006c\u0065\u0072\u0074('\u0031')>
这里我们想是否可以结合上面的HTML编码呢?
我们按照他的顺序反过去,先JS编码然后HTML解码
<img src="1"
onerror=\u0061\u006c\u0065\u0072\u0074('\u0031')>
浏览器读到了<标签开始构造语法树,然后HTML解码,解码之后发现onerror于是进行一个JS解码
成功弹窗
这一性质可以延伸到开发人员的一个马虎
比如开发人员单纯的设置HTML实体编码为防御xss的手段,但是用户输入点确实在alert中
<img src = "https://text.com" onclick = 'alert(输入点)'>
如果用户正常输入的话凡是存在< ," 等都能被转码
但是攻击者可以通过语句");alert("test 然后HTML编码即可绕过
<img src = "https://gss1.bdstatic.com" onclick =
'alert("FIRST XSS |
");alert("test")'>
发现弹窗了两次,是因为服务端进行一个HTML解码发现存在两个alert()弹窗于是直接弹
所以对于这种情况,正确防御XSS的方法
应该是先javascript编码然后再进行HTML编码
对于服务器而言它看到的内容应该是
1、首先
\u0027\u0029\u003b\u0061\u006c\u0065\u0072\u0074\u0028\u0027\u0053\u0052\u0043
经过第一步HTML解码后变为\u0027\u0029\u003b\u0061\u006c\u0065\u0072\u0074\u0028\u0027\u0053\u0052\u0043
2、JavaScript解析器工作,\u0027\u0029\u003b\u0061\u006c\u0065\u0072\u0074\u0028\u0027\u0053\u0052\u0043变为');alert('SRC,刚才已经讲过JavaScript解析时只有标识符名称不会被当做字符串,控制字符仅会被解析为标示符名称或者字符串,因此\u0027被解释成单引号文本,\u0028和\u0029被解释成为圆括号文本,不会变为控制字符被解析执行。
在这里采用的先JS编码后HTML编码中只弹窗了一次。
URL编解码
讨论URL编码我们采用新的语句
<a href = "javascript:alert(3)">hhhhh<a>
在这里我们以浏览器视角来看
浏览器看到<满足HTML解码的条件,然后看到href 满足了URL编码额条件,最后看到javascript满足JS 解码的条件
作为攻击者我们应该反过来首先进行一个JS编码
<a href="javascript:\u0061\u006c\u0065\u0072\u0074(3)">hhhhhh</a>
然后进行一个URL编码
<a
href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(3)">hhhhhh</a>
最后进行一个HTML编码
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(3)">hhhhhh</a>
有师傅提供了其他的例子:
<a onclick="window.open('value1')" href="javascript:window.open(value2)">
这里的value1:浏览器看到<标签,可以HTML解码,然后看到onclick可以进行JS解码,最后看到window.open可以进行URL解码
对于value2而言:浏览器看到<标签进行一个HTML解码,然后看到href进行一个URL解码,再之后看到javascript进行一个JS解码,最后看到了window.open编码进行一个URL解码
总结
我们在学习了浏览器的编解码机制之后,对于一个XSS的产生有了更加明确的想法
同时对于一些XSS的方式还是要考虑不同情况分别编码
单一的靠一种编码想一劳永逸的防住XSS是不可能的。
参考资料:
http://whip1ash.cn/2018/07/01/HTML-Javscript-self-decode/
https://www.yuque.com/kkdlong/eiwne5/fpl8ob?language=en-us
https://security.yirendai.com/news/share/26
转自先知社区
打赏我,让我更有动力~
 返回:技术文章投稿区
返回:技术文章投稿区
 漏洞文章
漏洞文章

